STAT 29000: Project 9 — Fall 2021
Motivation: Structured Query Language (SQL) is a language used for querying and manipulating data in a database. SQL can handle much larger amounts of data than R and Python can alone. SQL is incredibly powerful. In fact, Cloudflare, a billion dollar company, had much of its starting infrastructure built on top of a Postgresql database (per this thread on hackernews). Learning SQL is well worth your time!
Context: There are a multitude of RDBMSs (relational database management systems). Among the most popular are: MySQL, MariaDB, Postgresql, and SQLite. As we’ve spent much of this semester in the terminal, we will start in the terminal using SQLite.
Scope: SQL, sqlite
Dataset(s)
The following questions will use the following dataset(s):
-
/depot/datamine/data/movies_and_tv/imdb.db
In addition, the following is an illustration of the database to help you understand the data.
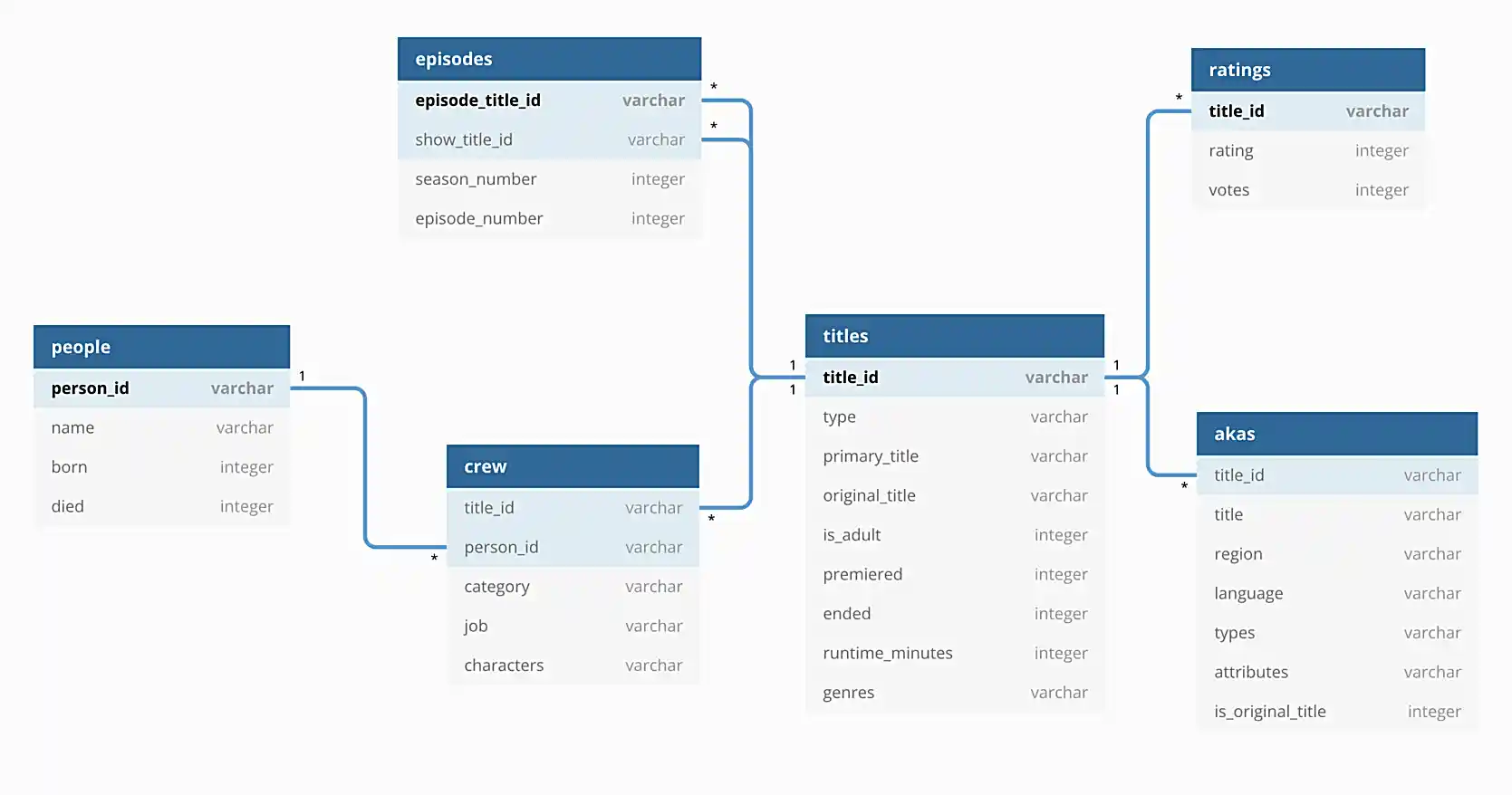
For this project, we will be using the imdb sqlite database. This database contains the data in the directory listed above.
To run SQL queries in a Jupyter Lab notebook, first run the following in a cell at the top of your notebook.
%load_ext sql
%sql sqlite:////depot/datamine/data/movies_and_tv/imdb.dbThe first command loads the sql extension. The second command connects to the database.
For every following cell where you want to run a SQL query, prepend %%sql to the top of the cell — just like we do for R or bash cells.
Questions
Question 1
Get started by taking a look at the available tables in the database. What tables are available?
|
You’ll want to prepend |
|
In sqlite, you can show the tables using the following query: Unfortunately, sqlite-specific functions can’t be run in a Jupyter Lab cell like that. Instead, we need to use a different query. |
-
Code used to solve this problem.
-
Output from running the code.
Question 2
Its always a good idea to get an idea what your table(s) looks like. A good way to do this is to get the first 5 rows of data from the table. Write and run 6 queries that return the first 5 rows of data of each table.
To get a better idea of the size of the data, you can use the count clause to get the number of rows in each table. Write an run 6 queries that returns the number of rows in each table.
|
Run each query in a separate cell, and remember to limit the query to return only 5 rows each. You can use the |
Relevant topics: queries, useful example
-
Code used to solve this problem.
-
Output from running the code.
Question 3
This dataset contains movie data from imdb.com (an Amazon company). As you can probably guess, it would be difficult to load the data from those tables into a nice, neat dataframe — it would just take too much memory on most systems!
Okay, let’s dig into the titles table a little bit. Run the following query.
SELECT * FROM titles LIMIT 5;As you can see, every row has a title_id for the associated title of a movie or tv show (or other). What is this title_id? Check out the following link:
At this point, you may suspect that it is the id imdb uses to identify a movie or tv show. Well, let’s see if that is true. Query our database to get any matching titles from the titles table matching the title_id provided in the link above.
|
The |
Relevant topics: queries, useful example
-
Code used to solve this problem.
-
Output from running the code.
Question 4
That is pretty cool! Not only do you understand what the title_id means inside the database — but now you know that you can associate a web page with each title_id — for example, if you run the following query, you will get a title_id for a "short" called "Carmencita".
SELECT * FROM titles LIMIT 5;title_id, type, ... tt0000001, short, ...
If you navigate to www.imdb.com/title/tt0000001/, sure enough, you’ll see a neatly formatted page with data about the movie!
Okay great. Now, if you take a look at the episodes table, you’ll see that there are both an episode_title_id and show_title_id associated with each row.
Let’s try and make sense of this the same way we did before. Write a query using the where clause to find all rows in the episodes table where episode_title_id is tt0903747. What did you get?
Now, write a query using the where clause to find all rows in the episodes table where show_title_id is tt0903747. What did you get?
Relevant topics: queries, useful example
-
Code used to solve this problem.
-
Output from running the code.
Question 5
Very interesting! It looks like we didn’t get any results when we queried for episode_title_id with an id of tt0903747, but we did for show_title_id. This must mean these ids can represent both a show as well as the episode of a show. By that logic, we should be able to find the title of one of the Breaking Bad episodes, in the same way we found the title of the show itself, right?
Okay, take a look at the results of your second query from question (4). Choose one of the episode_title_id values, and query the titles table to find the title of that episode.
Finally, in a browser, verify that the title of the episode is correct. To verify this, take the episode_title_id and plug it into the following link.
So, I used tt1232248 for my query. I would check to make sure it matches this.
Relevant topics: queries, useful example
-
Code used to solve this problem.
-
Output from running the code.
Question 6
Okay, you should have now established that every row in the titles table correlates to the title of a single episode of a tv show, the tv show itself, a movie, a short, or any other type of media that has a title! A single tv show, will have both a title_id for the name of the show itself, as well as a title_id for each individual episode.
What if we wanted to get a list of episodes (including the titles) for the show? Well, the best way would probably be to use a join statement — but we are just getting started, so we will skip that option (for now).
Instead, we can use what is called a subquery. A subquery is a query that is embedded inside another query. In this case, we are going to use a subquery to find all the episode_title_id values for Breaking Bad, and use the where clause to filter our titles from our titles table where the title_id from the titles table is in the result of our subquery.
The following are some steps to help you figure this out.
-
Write a query that finds all the
episode_title_idvalues for Breaking Bad.We only need/want to keep the
episode_title_idvalues, not the other fields likeshow_title_idorseason_numberorepisode_number. -
Once you have your query, use it as a subquery to find all the
title_idvalues for Breaking Bad.Here is the general "form" for this.
SELECT _ FROM (SELECT _ FROM _ WHERE _) WHERE _;Where the part surrounded by parentheses is the subquery.
Of course, for this question, we just want to see if the
title_idvalues are in the result of our subquery. For this, we can use theinoperator.SELECT _ FROM _ WHERE _ IN (SELECT _ FROM _ WHERE_);
When done correctly, you should get a list of all of the titles table data for every episode in Breaking Bad, cool!
Relevant topics: queries
-
Code used to solve this problem.
-
Output from running the code.
Question 7
Okay, this subquery thing is pretty useful, and a little confusing. How about we practice some more?
Just like in question (6), get a list of the ratings from the ratings table for every episode of Breaking Bad. Sort the results from highest to lowest by rating. What was the title_id of the episode with the highest rating? What was the rating?
Relevant topics: queries
-
Code used to solve this problem.
-
Output from running the code.
Question 8
Write a query that finds a list of person_id values (and just person_id values) for the episode of Breaking Bad with title_id of tt2301451. Use the crew table to do this. Limit your results to actors only.
Relevant topics: queries
-
Code used to solve this problem.
-
Output from running the code.
Question 9
Use the query from question (8) as a subquery to get the following output.
Name | Approximate Age
Use aliases to rename the output. To calculate the approximate age, subtract the year the actor was born from 2021 — that will be accurate for the majority of people.
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. |